728x90
반응형
논문 : GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
URL : arxiv.org/abs/1903.10955
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
We present an efficient 3D object detection framework based on a single RGB image in the scenario of autonomous driving. Our efforts are put on extracting the underlying 3D information in a 2D image and determining the accurate 3D bounding box of the objec
arxiv.org
저자 : Buyu Li, Wanli Ouyang, Lu Sheng, Xingyu Zeng, Xiaogang Wang
Publish : 2019, CVPR
[Intro Summary]
- 해결하고자하는 문제
- 오직 monocular RGB 로 3dod 하기
- 지금까지 시도해왔던 방법들
- mono3d : traditional 2D → sliding window → covering objects well
- 기존 방법들의 한계
- 계산량도 많고 불필요한 과정도 많음
- 이번 논문에서 시도할 방법
- assume : 2D detection is very good! → Guidance으로 사용
- visible surface에 대한 feature로 3D box refinement →Quality aware loss
- 논문이 가지게 되는 Contributions
- 2D 정보를 Base로 self-supervised 한 guidance를 만듬
- Quality aware loss로 3D box 바로 regression 가능
- visible surface에 대한 feature 고려는 기존에 없던 방법
[Summary] Main Points of this paper
- Overview

- Insight : 2D Detector은 이미 충분히 믿을만한 성능을 가지고 있다. → 이것의 결과부터 시작하면 기존의 문제였던 복잡성을 많이 줄일 수 있음
- 또 2D의 결과를 projective 결과로 보면 inverse 연산을 통해서 3D에 대한 prior 정보도 얻어낼 수 있음.
- 이후 3D BB의 정확도를 높이기 위해 visible surface에 대한 feature extraction을 실행 → 더 정밀한 BB
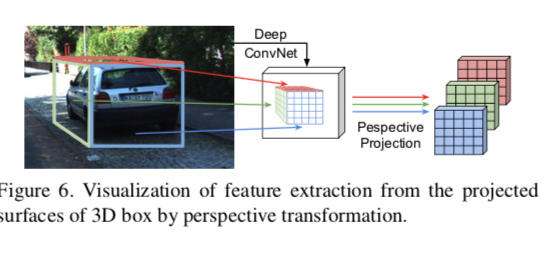
[Strengths] Clearly explain why these aspects of the paper are valuable.
- 이미 성능이 올라왔다는 2D 디텍션을 활용한 방법이라는 점에서 기존 방법들과 차별이 있음
- surface를 고려해서 정밀도를 높이는 점
- 0 아니면 1이였던 문제(classification)을 quality -aware 을 통해 regression으로 바꿈 → 더 정밀하게 positive를 누날 수 있음.
[Weaknesses] Clearly explain why these aspects of the paper are weak.
- 2D Detection 성능에 의존적
- Depth를 추정할때 2D 박스 기반으로 3D의 높이를 추정하고 이후 car라는 object의 일반성을 추론해서 비율로써 높이를 측정해서 center을 뽑는데 이는 car 라는 object에 너무 종속적이고 활용범위가 작아짐
- surface feature extraction이 과연 필요할까 에 대한 의문? → 오히려 어려운 Task에 대해서 더 잘 잡는데 왜일까?
[Why accepted?] What is the contribution of the paper? Or novelty
- super vision 없이 2D에서 3D 정보를 얻어내는 것에 대한 novelty
[Appendix]
반응형

